首先我們先在 graphAPI 子專案資料夾下面創建一個資料夾: schemaClass 來放我們所有的 schema python 檔
現在資料夾結構長這樣:
- api
- djangoAPI
+ graphAPI
migrations
- schemaClass
admin.py
apps.py
models.py
schema.py
tests.py
views.py
__init__.py
- manage.py
視線回到上次我們製作的 playData api
輸入值是 name,返回來的格式長這樣
[
{
ID: 2,
NAME: "Charmander",
LV: 35,
SKILL: "fire"
}
]
接下來我們進入 schemaClass 創建 __init__.py 跟 playDataSchema.py
開始定義資料的 schema
在 playDataSchema.py 中加入:
import graphene
class playDataSchema(graphene.ObjectType):
ID = graphene.Int()
NAME = graphene.String()
LV = graphene.Int()
SKILL = graphene.String()
然後回到 graphAPI/schema.py 編輯成以下:
import graphene
#--------- 新增以下
from collections import namedtuple
from .schemaClass.playDataSchema import playDataSchema
from api.api.playData import playData
#---------
class Query(graphene.ObjectType):
reverse = graphene.String(word=graphene.String(default_value='t'))
def resolve_reverse(self, info, word):
print(self)
return 'hello'
#--------- 新增以下 ------------------------
playData = graphene.List(playDataSchema, name = graphene.String())
def resolve_playData(self, info, name):
data = playData( {'name': name} )['data']
if len(data) > 0:
# --- 轉成 namedtuple ---
outDataNT = namedtuple('myData', [ key for key in data[0] ])
outData = [ outDataNT(**eachData) for eachData in data ]
# ----------------------
return outData
else:
return []
#-------------------------------------------
schema = graphene.Schema(query=Query)
graphene.List( schema 類別, 需要輸入的條件 ) 代表要返回一個 list (非陣列用 NonNull),其中每格裡面的型別都是第一格輸入的型別 (這邊是 playDataSchema)。
然後因為 graphene 預設是用 getattr() 這個函數抓值,所以我們要把回來的 dict 轉換成 namedtuple 型別 (這個型別可以用 getattr() 抓值)
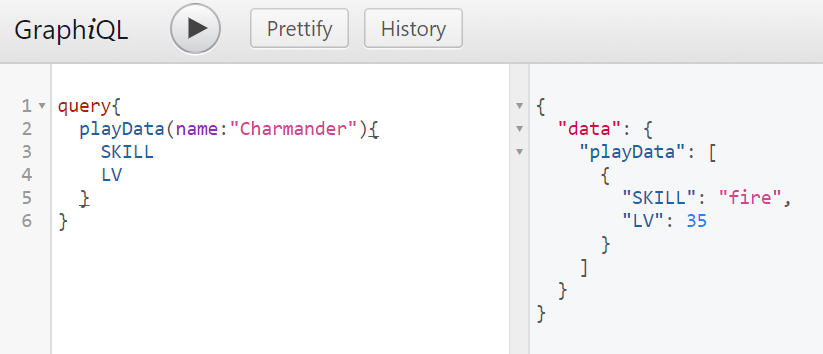
結束後 run server 就有結果嚕!
 flyingtao
flyingtao
